Thinking stateless and serverless: designing a shareable to-do app
Published September 27, 2022
I have been playing around with serverless computing for a while now and decided to develop a to-do list app as I though the project would be a good candidate for serverless computing. One of serverless’s limitations is that your code generally has to be stateless meaning the “server” or your code can’t really keep track of what happened during previous executions or requests. However, you can design applications with this limitation in mind and in some cases end up with a system that is more efficient and elegant than a stateful system.
Developing a to-do list app doesn’t sound particularly interesting. There are probably hundreds of thousands of them online and they are often chosen as example projects for web frameworks. But once you add the limitation of statefulness to the mix while trying to make the lists shareable between users, it actually becomes a nice little challenge.
Table of contents
What’s so interesting about serverless computing?
As someone who is hosting a few small websites and services for fun, I don’t want to spend any time managing any servers. Obviously, serverless solves that issue for me. I also don’t want to be spending any money on these projects. Most serverless platforms have generous free tiers with a lot of compute time which fits these projects perfectly.
Latency is also an issue with self-hosting my projects. I live in Belgium while most people that read my posts don’t. I would love for my projects to load at roughly the same speed regardless of where you’re visiting it from. This is an easy problem to solve for static sites: just use a Content Delivery Network (CDN). For dynamic content that is computed on the fly, this used to be quite a complex issue to solve. With serverless, is it very straightforward: your code (generally) gets executed at the datacenter closest to your client. I will demonstrate the speed later in this post, it truly feels like black magic.
Database design and storage
A user visiting the site should be able to create multiple lists with each list containing multiple “to-do” items that can be checked. The list should also be shareable with a link. If I write these models in TypeScript, it might look something like this:
type Item = {
value: string;
checked: boolean;
}
type List = {
title: string;
items: Item[];
}
type User = {
lists: List[];
}
This looks like something that would fit quite nicely in a relational database, right? There’s a one-to-many relationship between users and lists and a one-to-many relationship between lists and items. Each model (or entity) would have its own table. The problem is that relational database servers require a server to run. SQL queries can also be computationally expensive and time-consuming which is not good when you are being billed per millisecond of usage.
What we would really like to use is one of the serverless database offerings such as Amazon DynamoDB or Cloudflare Workers KV. Both of these offerings are key-value stores which generally speaking aren’t really suited for datasets containing many relations but can be very fast if you don’t.
At this point, we need to think of a way to fit this data structure into a key-value database. What we could do is identify the list with a Universally Unique Identifier (UUID) and condense lists and items into one data type, like so:
type List = {
uuid: string;
items: {
value: string;
checked: boolean;
}[];
}
In the key-value store, the key would be the list’s UUID and the value would be some serialized format of the list such as JSON.
We could even do something similar for the user data type: assign a UUID to the user and make the user data type store an array of lists.
type User = {
uuid: string;
lists: {
uuid: string;
items: {
value: string;
checked: boolean;
}[];
}[];
}
But think of how other users might access this list if the user decides to share it. They would have to have the user’s UUID to see the array of lists as well as the list’s UUID to find the exact list. This is something I often struggle with while using NoSQL databases. Nearly all datasets contain some type of relations. Luckily, in this case, JSON Web Tokens (JWTs) offer an elegant solution to this problem.
JWTs are often used in web development for stateless session management. The token, which is stored in the client’s browser, contains some data as well as a signature for that data from the server. If the data changes without permission from the server, it won’t match the signature.
We can now save the lists in the key-value store and leverage JWTs to save the UUIDs or references to a user’s lists in their browser. The user cannot add someone else’s list’s UUID by simply changing their JWT in their browser as changes in the data wouldn’t match the signature anymore. And for user’s accessing a shared list, the list can now be fetched in one request with just the list’s UUID.
This is what the system currently looks like:
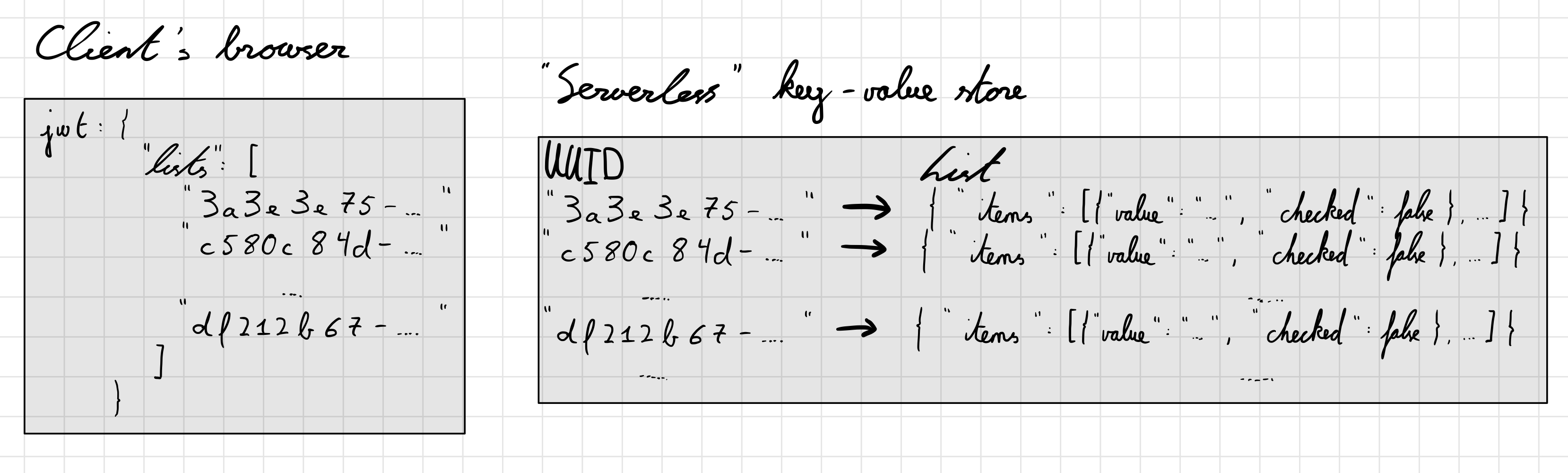
Notice how we were able to outsource the work of storing the user’s data to the client itself and how we were able to simplify the key-value store design by doing so.
Sharing lists with others
Implementing sharing doesn’t sound too difficult at first. We could modify the list data type to store which user’s the list has been shared with (assuming the user has a UUID) as well as the permissions:
type User = {
uuid: string;
lists: {
uuid: string;
items: {
value: string;
checked: boolean;
}[];
shared: {
userUuid: string;
writable: boolean;
}[];
}[];
}
However, this would require the user to know the UUID of the user they are sharing their list with. This creates a few issues:
- How does the user find their friend’s UUID?
- What if the user has never visited the app before and doesn’t have a UUID?
The first issue could be solved by using some kind of invitation system where the friend’s UUID is retroactively added to the shared list. The second issue could maybe be fixed by creating the account before the accepting the invite through a link. These solutions would require a lot of extra code and would introduce a lot of complexities which we don’t want.
Thinking back to the previous section, we were able to move some of the work from the server to the client by using a JWT. The JWT gave us a way to store data in a stateless way, on the client, while ensuring that the data is verified or signed by the server. We could do something similar for sharing lists.
To fetch a list from the database, we just need the list’s UUID. When sharing the list with a friend, we would like to be able to choose whether the list should be just readable or also writable. In theory, we could send these two parameters (UUID and writable) in the URL to a friend and let the server fetch the list and depending on the writable parameter, also let the friend write the list. There are two problems with this approach:
- A user could change the list UUID parameter and view a list they shouldn’t have access to
- A user could change the writable parameter and edit a list they couldn’t be able to edit
If we sign these two parameters, include the signature in the same URL and then check if the signature matches on the server, then we solve both issues. Now, if the user changes at least one of the parameters, the signature won’t match and the list won’t load and won’t be written to.
This is what it now looks like for the user sharing the link to their list:
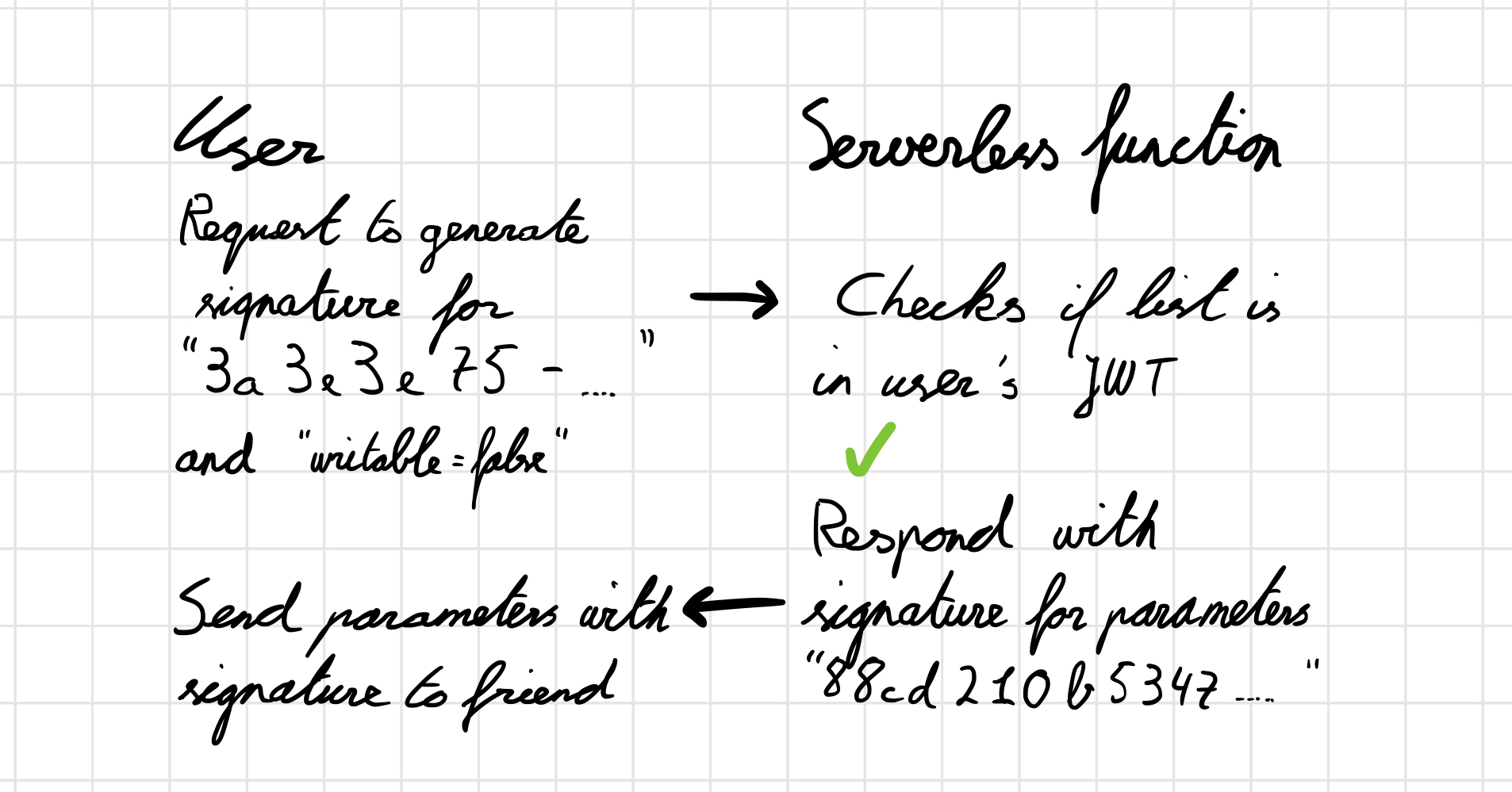
And this is what it looks like for something trying to access a list which they have access to and a list they don’t have access to:

Choosing a serverless platform
There are quite a few serverless platforms you can choose from: Google Cloud Functions, Cloudflare Workers, AWS Lambda, Deno Deploy and Vercel Functions.
I chose Cloudflare for the following reasons:
- They offer a basic key-value store, something I this project needed.
- They use web compatible APIs such as
fetchwhich means you don’t have to waste any time learning new libraries and you can use documentation from MDN. - Cloudflare Workers don’t suffer from the same “cold-start” times that plague platforms like Google Cloud Functions and AWS Lambda. This is because of some clever technology they are using from Chrome. The trade-off you make for this is that you don’t have access to the Node.js standard library.
- It integrates nicely with their static site hosting which I use for the frontend.
Deno Deploy is another new option that I have used before which I would also recommend. In general, I’d really recommend choosing a platform that offers a good developer experience. For me, this means being able to deploy functions quickly without requiring loads of configuration and a clear interface that doesn’t feel like navigating through a maze.
Note
I am in no way affiliated with any of the organisations I just talked about.
Limitations of Cloudflare’s key-value database
There’s an interesting caveat with Cloudflare’s key-value store (Workers KV) which is that it lacks consistency. This means that one function execution might read a different value than another execution, even though they’re accesing the same key at the same time. This is because Workers KV “stores data in a small number of centralized data centers, then caches that data in Cloudflare’s data centers after access”. If you happen to be connected to a data center that hasn’t cached the newest version of your list, then you will see an older version. Cloudflare advertise this system as “eventually-consistent” with data taking up to a minute to propagate to all other locations.
Their “up to a minute” claim was concerning to me at first. However, when I tested it, it seemed to never take more than a few seconds. Keep in mind that people are also likely to share lists with people that they are physically close to, so the chances that they’ll both be connecting to the same data center should be high. This is a trade-off I’m willing to make.
Developing the serverless function
Writing code for Cloudflare Workers went very smoothly as they use web APIs which I am very familiar with. This also makes it relatively easy to adapt if I would ever like to host it on Deno which could be serverless or on a server.
I chose to write it in TypeScript instead of plain JavaScript. You can find the actual code and documentation for the endpoints in the this directory of the GitHub repository.
Developing the frontend
The last thing needed now was a user interface that connects with the frontend. The site is statically generated with Svelte. I won’t bore you too much with the details here as this post is more about the serverless architecture of the project, but there are some interesting decisions I had to make for the site which I documented here. You can also find the codebase for the site there.
Result
This is what it the site sharemytodo.com looks like:
Here’s a small summary of all the technologies I used to build it:
- Server is written in TypeScript and hosted by Cloudflare Workers
- Storage for the lists is on Cloudflare Workers KV
- Site is written in Svelte (with TypeScript) and hosted by Cloudflare Pages
Performance
The Chrome DevTools network tab shows us the load times for the Cloudflare Worker endpoints. The lists endpoint creates the initial list for the user and the share-list endpoint requests generate the HMACs for that list: one writable and one non-writable.
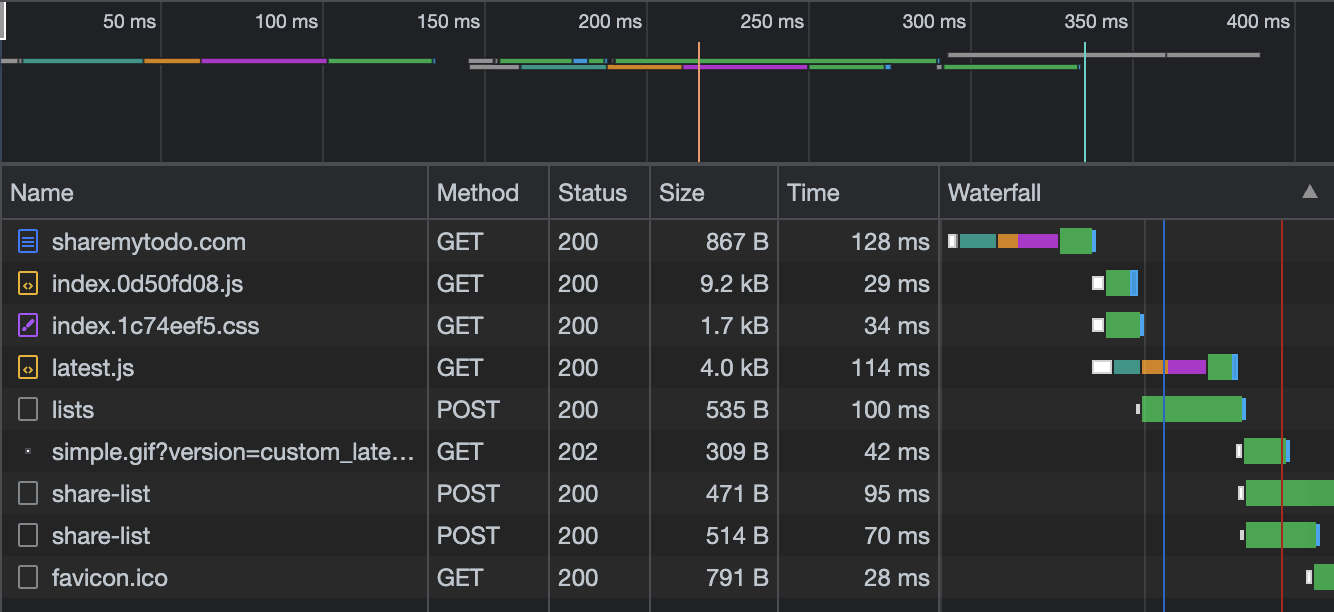
The longest Worker request takes 100ms. Currently, I am roughly 25 kilometers from Cloudflare’s Brussels datacenter. Note that this is not a “cold start”. I have noticed that the initial request can sometimes take up to 700ms when I haven’t visited the site in a while.
For a simple load test, I used k6 with the following script:
import http from 'k6/http';
import { sleep } from 'k6';
export const options = {
vus: 100,
duration: '15s',
};
export default function() {
http.post('https://sharemytodo.com/api/lists');
}
This simulates 100 users in parallel constantly creating lists for 15 seconds. These are the results:
running (15.0s), 000/100 VUs, 45069 complete and 0 interrupted iterations
default ✓ [======================================] 100 VUs 15s
data_received..............: 218 MB 15 MB/s
data_sent..................: 3.3 MB 219 kB/s
http_req_blocked...........: avg=6.07ms min=0s med=0s max=7.15s p(90)=1µs p(95)=1µs
http_req_connecting........: avg=5.86ms min=0s med=0s max=7.03s p(90)=0s p(95)=0s
http_req_duration..........: avg=27.16ms min=13.17ms med=26.46ms max=295.78ms p(90)=32ms p(95)=34.65ms
http_req_failed............: 100.00% ✓ 45069 ✗ 0
http_req_receiving.........: avg=527.69µs min=16µs med=101µs max=20.44ms p(90)=1.73ms p(95)=2.31ms
http_req_sending...........: avg=45.73µs min=6µs med=34µs max=6.49ms p(90)=66µs p(95)=96µs
http_req_tls_handshaking...: avg=212.18µs min=0s med=0s max=173.09ms p(90)=0s p(95)=0s
http_req_waiting...........: avg=26.58ms min=13.05ms med=25.89ms max=295.6ms p(90)=31.35ms p(95)=33.88ms
http_reqs..................: 45069 2996.185911/s
iteration_duration.........: avg=33.3ms min=13.24ms med=26.54ms max=7.24s p(90)=32.12ms p(95)=34.86ms
iterations.................: 45069 2996.185911/s
vus........................: 100 min=100 max=100
vus_max....................: 100 min=100 max=100
Let’s look at the iteration_duration and iterations lines. In total, 45069 requests were made in a timespan of 15 seconds. The average request took just 33 milliseconds. Only 5% of requests took longer than 34 milliseconds. This shows how scalable and consistent serverless computing can be.
Summary
I really enjoyed working on this project. This is the first time I’ve built a fully serverless application and I’m pleased with how well it turned out. It forces you to architect your application quite carefully, limiting the amount of resources you have access to and encouraging you to be as lean and as efficient as possible with your code. Of course, these ideas are always encouraged in software engineering, but even more so if you are being billed based on your usage.
In this case, it took a few tries, but I am very satisfied with the resulting design and code. The code for the Cloudflare Worker is roughly 250 lines and allows users to create, delete and share lists and modify or view lists that are either shared or private. For me, personally, that’s an impressive amount of functionality to have in 250 lines of code and it’s a testament to the elegant design that stateless systems can have.
